
Im September 2025 verbot das Landgericht Hamburg der Firma X.AI per einstweiliger Verfügung, weiter zu behaupten, die NGO Campact werde „zu großen Teilen aus Bundesmitteln" finanziert. Das Problem: Diese Falschbehauptung kam nicht von einem Mitarbeiter, sondern vom KI-Chatbot Grok. Bei Verstoß gegen die Verfügung drohen bis zu 250.000 € pro Fall. Das Gericht stellte klar: Allgemeine Hinweise wie „This post was created by an AI" entlasten den Betreiber nicht – auch nicht die Tatsache, dass das Modell „nur halluziniert" hat (LG Hamburg, Beschluss vom 23.09.2025, Az. 324 O 461/25).
Damit ist endgültig angekommen, was Praktiker seit zwei Jahren erleben: Halluzinationen sind kein technisches Detail mehr, sondern ein hartes Geschäftsrisiko. Sie kosten Geld (Air Canada zahlte 812,02 CAD an einen Witwer, weil der Chatbot eine Rückerstattungsregel erfunden hatte – B.C. Civil Resolution Tribunal, Februar 2024), Reputation (DPD-Bot beschimpft Kunden, Januar 2024) und – neu seit 2025/2026 – auch Haftung.
Gleichzeitig gilt: Halluzinationen sind nicht „lösbar" wie ein Bug. Sie sind eine Eigenschaft generativer KI. Das Ziel ist nicht 0 % – das Ziel ist vorhersagbares, dokumentiertes, kontrolliertes Risiko.
Dieser Leitfaden zeigt, was Halluzinationen 2026 wirklich sind, warum gerade die neuen Reasoning-Modelle mehr halluzinieren als ihre Vorgänger, was der EU AI Act ab dem 2. August 2026 verlangt – und welche sieben Hebel deutsche Unternehmen praktisch einsetzen können, ohne KI ganz zu verbieten.
Die wichtigsten Zahlen auf einen Blick
64 % der Organisations-Leader nennen Inaccuracy als das am häufigsten genannte Risiko verantwortlicher KI – vor regulatorischer Compliance (63 %) und Cybersecurity (60 %) (Stanford AI Index Report 2025, Kapitel 3, Zitat aus McKinsey-Erhebung).
Reasoning-Modelle halluzinieren mehr, nicht weniger: Auf OpenAIs eigener Faktentest-Benchmark PersonQA liegt die Halluzinationsrate bei o3 bei 33 % und bei o4-mini bei 48 % – gegenüber 16 % für o1 (TechCrunch, 18. April 2025; OpenAI System Card).
LG Hamburg, 23.09.2025 (Az. 324 O 461/25): X.AI haftet für falsche Behauptungen von Grok. Ordnungsgeld bis 250.000 € pro Verstoß. Disclaimer entlasten Betreiber nicht.
EU AI Act, Art. 15: Hochrisiko-KI-Systeme müssen „appropriate levels of accuracy" erreichen und die Accuracy-Metrik in den Instructions for Use deklarieren. Geltung ab 2. August 2026.
Über 1.400 dokumentierte Gerichtsfälle weltweit (Stand Mai 2026, Damien-Charlotin-Datenbank) mit KI-Halluzinationen im Schriftsatz – Sanktionen reichen typischerweise von einigen hundert bis mehreren tausend US-Dollar pro Fall, plus berufsrechtliche Konsequenzen.
Forrester prognostiziert für 2026 mehr als 10 Mrd. USD direkten Schaden in B2B-Unternehmen durch ungesteuerte GenAI-Nutzung – getrieben durch Halluzinationen und fehlende Governance.
1. Was eine KI-Halluzination wirklich ist – und was nicht
Im Unternehmenskontext werden „Halluzinationen" häufig als Sammelbegriff für alles benutzt, was schiefläuft. Sauberer ist eine Unterscheidung in drei Kategorien, die in Studien und in der EU-Regulierung erkennbar wird:
Faktische Halluzination
Das Modell erfindet konkrete Fakten: Namen, Datumsangaben, Paragrafen, Studien, Urteile, Produkteigenschaften. Das ist die klassische „Erfindung", die in Anwaltsfällen und Chatbot-Vorfällen auftritt.
Kontext-Halluzination
Das Modell weicht von den Quellen ab, die ihm gegeben wurden (RAG). Zahlen werden „glatter" formuliert, Bedingungen weggelassen, Aussagen aus dem Kontext extrapoliert.
Selbstüberschätzungs-Halluzination
Das Modell behauptet, etwas getan zu haben, was es nicht getan hat („Ich habe das Dokument geprüft …") oder Tools genutzt zu haben, die gar nicht aufgerufen wurden. Besonders verbreitet bei Reasoning-Modellen.
Was eine Halluzination nicht ist: ein offensichtlicher Witz, eine bewusst kreative Antwort, ein Tippfehler oder eine fehlende Information bei klarer „Ich weiß es nicht"-Antwort. Genau diese Fähigkeit, „ich weiß es nicht" zu sagen, ist 2026 das wichtigste Qualitätsmerkmal von Unternehmens-KI – und der entscheidende Unterschied zwischen einem konsumenten-Chatbot und einer Enterprise-Plattform.
Wer das Grundprinzip generativer Modelle verstehen möchte: Ein LLM sagt nicht den „wahren" Satz vorher, sondern den wahrscheinlichsten nächsten Token. Wenn die Trainingsdaten zu einem Thema dünn oder widersprüchlich sind, produziert das Modell trotzdem flüssige, plausibel klingende Texte. Das ist kein Bug – das ist die Funktionsweise. Wer mehr darüber wissen will, findet im Artikel Retrieval Augmented Generation erklärt die technische Vertiefung.
2. Warum Reasoning-Modelle 2026 mehr halluzinieren – und was das für Sie heißt

Die intuitive Annahme lautet: Modelle, die länger nachdenken, machen weniger Fehler. Reasoning-Modelle wie OpenAI o3 / o4-mini, Anthropic Claude Sonnet 4.6 / Opus 4.7 mit extended thinking und Gemini 3 Deep Think verbringen mehr Rechenzeit pro Antwort. Logisch wäre also: höhere Qualität, weniger Erfindungen.
Die Realität sieht anders aus. In der eigenen System Card von OpenAI (April 2025, weiter dokumentiert in TechCrunch, PCWorld, TechSpot) liegen die Halluzinationsraten auf der internen Benchmark PersonQA (Fragen über Personen, die das Modell faktisch beantworten soll):
| Modell | Halluzinationsrate (PersonQA) | Einordnung |
|---|---|---|
| OpenAI o1 | ~ 16 % | Erste Reasoning-Generation, vergleichsweise konservativ |
| OpenAI o3-mini | ~ 14,8 % | Kleineres Modell, weniger Behauptungen pro Antwort |
| OpenAI o3 | ~ 33 % | Mehr aktive Behauptungen → mehr Fehler in absoluter Zahl |
| OpenAI o4-mini | ~ 48 % | Höchste Rate, besonders bei „nichts gefunden"-Szenarien |
OpenAI selbst kommentierte diesen Effekt mit „more research is needed". Die plausibelste Hypothese (auch vom unabhängigen Auswertungslabor Transluce gestützt): Reasoning-Modelle treffen pro Antwort mehr und detailliertere Aussagen – also auch mehr richtige und mehr falsche. Dazu kommt ein neues Phänomen: Modelle erfinden, dass sie ein Tool aufgerufen oder einen Code ausgeführt hätten, der niemals lief.
Was das für Ihre Plattform-Entscheidung bedeutet:
Reasoning-Modus ist kein Allheilmittel
-
Setzen Sie Reasoning-Modelle gezielt ein – für Aufgaben, bei denen mehr Schritte und mehr Eigenrecherche wirklich helfen (Code, Analyse, Strategie). Nicht als Standard für Faktenfragen.
-
Trennen Sie „Wissensanfragen" von „Denkaufgaben". Für Wissensanfragen ist ein klassisches Modell mit RAG fast immer die bessere Wahl.
-
Loggen Sie, wenn ein Modell behauptet, ein Tool benutzt zu haben. Hat es das tatsächlich? In Plattformen wie Plotdesk ist diese Auditierung Teil des Standards.
-
Vermeiden Sie Multi-Modell-Lock-in. Wer 2026 nur auf ein Reasoning-Modell setzt, hat keine Wahl, wenn die Halluzinationsrate steigt. Mehr dazu im Artikel Multi-Modell-KI-Strategie.
3. Vier reale Fälle, die jedes Unternehmen kennen sollte
Halluzinationen wirken abstrakt – bis sie vor Gericht landen. Die folgenden vier Fälle sind alle durch öffentliche Quellen belegt und gehören zum Pflichtwissen jedes Entscheiders, der KI im eigenen Haus einführt.
| Fall | Was passierte? | Konsequenz | Lehre für Ihr Unternehmen |
|---|---|---|---|
| LG Hamburg 09/2025 324 O 461/25 |
Grok behauptete falsch, eine NGO werde „zu großen Teilen aus Bundesmitteln" finanziert. | Einstweilige Verfügung gegen X.AI, Ordnungsgeld bis 250.000 € pro Verstoß. Disclaimer reichen nicht. | Auch bei klar gekennzeichneten KI-Antworten haften Sie für Falschaussagen über Dritte. |
| Air Canada Chatbot 02/2024 Moffatt-Fall |
Chatbot erfindet eine Bereavement-Fare-Regel, die so nicht existiert. | Schadenersatz 812,02 CAD vor dem B.C. Civil Resolution Tribunal. Argument „separate legal entity" verworfen. | Ihr Chatbot ist Teil Ihres Unternehmens. Was er sagt, ist Ihre Aussage. |
| Mata v. Avianca 06/2023 | Anwalt reicht Schriftsatz mit sechs frei erfundenen Präzedenzfällen ein, von ChatGPT generiert. | Sanktion 5.000 USD durch Richter P. Kevin Castel, S.D.N.Y., und Pflicht zur Mitteilung an die fälschlich attribuierten Richter. | Jede KI-Ausgabe gehört verifiziert, bevor sie nach außen geht. Besonders in Wissensberufen. |
| DPD Bot 01/2024 | Update am Support-Bot führt dazu, dass dieser Kunden beschimpft und DPD selbst als „worst delivery firm" bezeichnet. | Sofortige Abschaltung des KI-Teils, massiver PR-Schaden (BBC, The Independent, TechSpot). | Regelmäßiges Red Teaming und Guardrails sind Pflicht – nicht nice-to-have. |
Die juristische Faustregel
Eine 2024 angelegte und kontinuierlich gepflegte Datenbank des Forschers Damien Charlotin zählt mit Stand Mai 2026 über 1.400 dokumentierte Gerichtsfälle weltweit, in denen KI-Halluzinationen in Schriftsätzen aufgetaucht sind. Die Sanktionen in den USA reichen typischerweise von einigen hundert bis mehreren tausend US-Dollar, plus berufsrechtliche Konsequenzen. Für Unternehmen heißt das: Sobald eine KI-Antwort den Weg in ein offizielles Dokument findet, haftet der Mensch, der sie nicht überprüft hat – nicht der KI-Anbieter.
4. Was der EU AI Act ab August 2026 von Ihnen verlangt
Anders als oft behauptet schreibt der EU AI Act keine Halluzinationsrate von „unter X Prozent" vor. Aber er macht aus Halluzinationen ein dokumentationspflichtiges Compliance-Thema. Drei Artikel sind besonders relevant:
Accuracy & Robustness
Hochrisiko-KI muss „angemessene" Genauigkeit über den Lebenszyklus erreichen. Die Accuracy-Metrik muss in den Instructions for Use deklariert werden. Geltung: ab 2. August 2026.
Human Oversight
Hochrisiko-Systeme müssen so gestaltet sein, dass natürliche Personen die KI effektiv beaufsichtigen können – inklusive der Möglichkeit, Empfehlungen zu hinterfragen und zu überschreiben.
Transparenz
Nutzer müssen verstehen können, wie das System funktioniert, welche Grenzen es hat und unter welchen Bedingungen es zuverlässig arbeitet. Halluzinationsrisiken gehören zur Pflichtinformation.
Wer nicht im Hochrisiko-Bereich aktiv ist (Standardfall im Mittelstand), wird durch Art. 15 nicht direkt getroffen. Aber: Über die AI-Literacy-Pflicht aus Artikel 4 (siehe unser Leitfaden zur KI-Schulungspflicht) müssen Sie sicherstellen, dass Ihre Mitarbeiter Halluzinationsrisiken kennen und einordnen können. Genau hier scheitern viele Unternehmen heute – nicht an der Technik, sondern an der Mitarbeiterbefähigung.
5. Die sieben Hebel: Was wirklich gegen Halluzinationen hilft
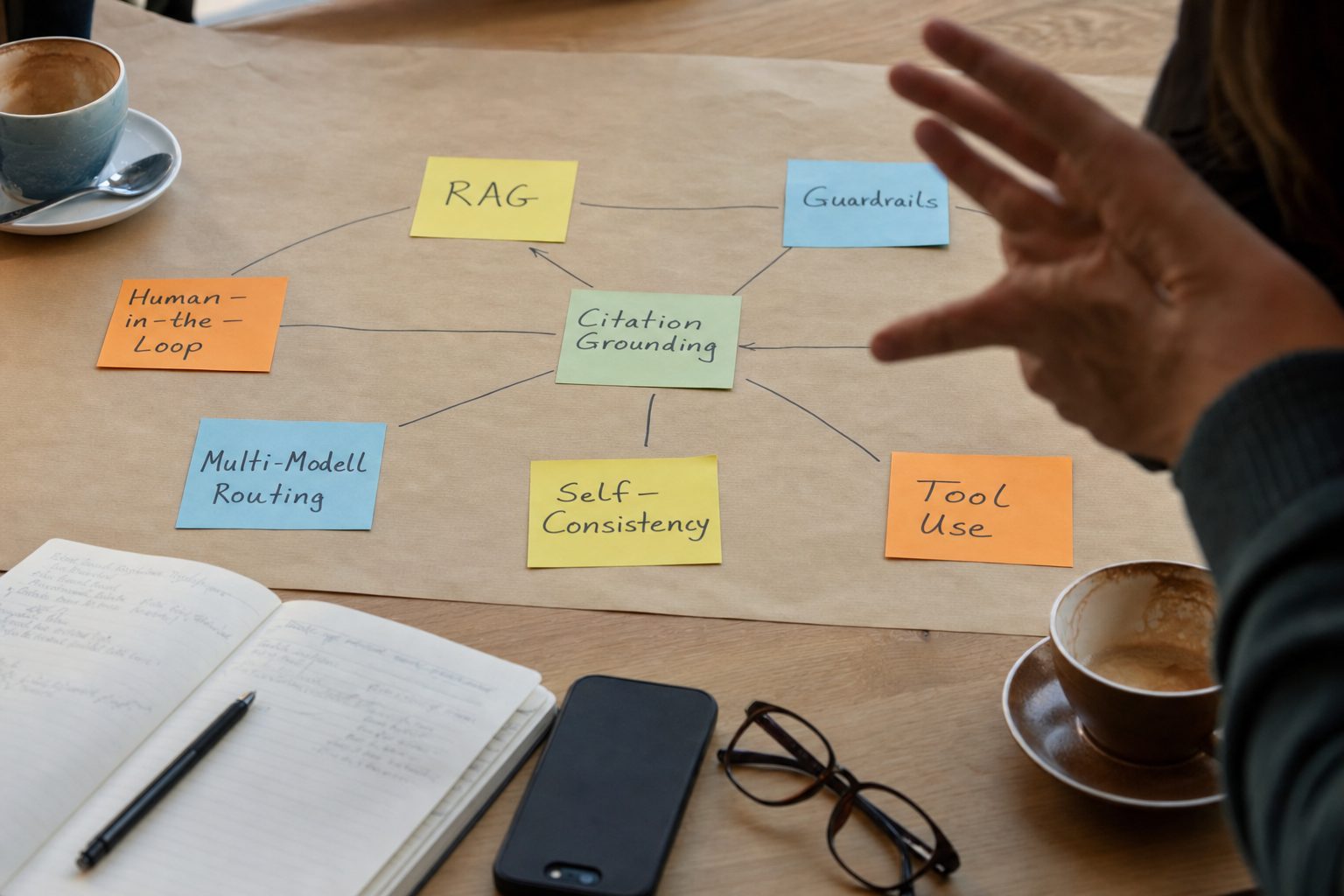
Die folgenden sieben Hebel sind durch wissenschaftliche Studien oder Praxisberichte belegt. Die Kunst liegt nicht darin, alle gleichzeitig zu nutzen, sondern die richtigen pro Use Case zu kombinieren.
Hebel 1: Retrieval Augmented Generation (RAG) statt freier Generation
Statt das Modell aus dem Gedächtnis antworten zu lassen, bekommt es Ihre eigenen Dokumente als Kontext: Wiki, Confluence, SharePoint, ERP-Daten, Produkthandbücher. Die Antwort wird dann auf Basis dieser Quellen gebildet – idealerweise mit Quellenangaben.
Studien aus 2025 zeigen messbare Effekte: Das Verfahren Finetune-RAG verbessert die Faktizität um +21,2 % gegenüber dem Basismodell (arXiv 2505.10792). Ein Public-Health-Anwendungsfall mit MEGA-RAG reduziert Halluzinationen um mehr als 40 % (PubMed 41132171). Und GraphRAG im Finanzbereich senkt Halluzinationen um 6 % bei gleichzeitig 80 % weniger Token-Verbrauch (ACL Anthology 2025.genaik-1.6).
In der Praxis ist das der wichtigste einzelne Hebel für die meisten Unternehmens-Use-Cases. Wer mit ChatGPT Enterprise startet und dann „warum ist es schlechter als gedacht?" fragt, hat in 80 % der Fälle einfach kein RAG im Einsatz.
Hebel 2: Citation Grounding („Quellen-Pflicht")
Eine Antwort ohne Quelle ist 2026 keine vertrauenswürdige Antwort mehr. Moderne Enterprise-Plattformen erzwingen pro Antwort eine Auflistung der genutzten Dokumente – verlinkt auf den exakten Abschnitt. Der psychologische Effekt: Nutzer prüfen nach. Der technische Effekt: Das Modell wird vorsichtiger, weil es seine Aussagen „belegen" muss.
Eine pragmatische Faustregel: Antworten ohne Quellen sind nicht für externe Kommunikation freigegeben. Diese eine Regel verhindert die meisten unangenehmen Vorfälle.
Hebel 3: Chain-of-Verification (CoVe) und Self-Consistency
Chain-of-Verification ist ein vierstufiges Prompting-Verfahren (Meta AI Research, arXiv 2309.11495): Das Modell erzeugt erst eine Antwort, generiert dann selbst Verifikationsfragen, beantwortet diese unabhängig und korrigiert seine ursprüngliche Antwort. Es funktioniert besonders gut für listenartige Aussagen („Liste alle …").
Self-Consistency lässt das Modell dieselbe Frage mehrfach beantworten und nimmt die häufigste Antwort. Auf Mathematikaufgaben (GSM8K) verbessert das die Genauigkeit um +17,9 %, auf SVAMP um +11 % (Google Research). Der Preis: höhere Kosten pro Anfrage. Lohnenswert dort, wo Genauigkeit > Geschwindigkeit ist.
Hebel 4: Tool Use statt freie Antwort
Wenn das Modell ein Tool aufrufen kann (Rechner, SQL, Websuche, interne API), muss es nicht raten. Statt zu fragen „Wie hoch war unser Umsatz Q1?" und auf eine geschätzte Antwort zu hoffen, ruft das Modell den SQL-Connector auf und bekommt die echte Zahl.
Konsequenz für die Plattform-Auswahl: Achten Sie auf echte Function Calling-Unterstützung über mehrere Modelle hinweg, plus Audit-Logs, die zeigen, welches Tool wann mit welchem Ergebnis aufgerufen wurde. Das ist auch die Voraussetzung für sinnvolle KI-Agenten im Unternehmen.
Hebel 5: Guardrails & Output-Validierung
Frameworks wie NVIDIA NeMo Guardrails (Open Source) bieten dedizierte Kategorien für Hallucination Detection und Fact Checking. Sie analysieren die Ausgabe bevor sie an den Nutzer geht und können sie blockieren oder neutralisieren. Meta liefert mit Llama Guard ein Open-Source-Modell für Input-/Output-Moderation, das laut NVIDIA-Dokumentation messbar besser ist als selbstgebaute Self-Check-Methoden.
Für Unternehmen, die KI in externe Kanäle (Chatbot, E-Mail-Autoreply) bringen, sind Guardrails kein Luxus, sondern Hygiene-Standard.
Hebel 6: Multi-Modell-Routing als Fallback
Jedes Modell hat Stärken und Schwächen. Claude Opus 4.7 ist 2026 besonders stark bei strukturiertem Reasoning, Gemini 3 Pro bei sehr langen Kontextfenstern, GPT-5.5 bei generalistischen Aufgaben und Websuche. Eine sinnvolle Architektur nutzt mehrere Modelle parallel – entweder per Voting (selbe Frage an zwei Modelle, abgleich der Antworten) oder per Routing (Aufgabentyp → passendes Modell).
In der Praxis ist das kein theoretisches Nice-to-have, sondern eine Versicherung gegen Modell-Drift, Preiserhöhungen und – siehe Punkt 2 – plötzliche Halluzinations-Sprünge zwischen Versionen.
Hebel 7: Human-in-the-Loop, dokumentiert
Der wirkungsvollste Hebel ist gleichzeitig der unglamouröseste: Menschen prüfen, bevor freigegeben wird. Das heißt nicht „jede E-Mail manuell lesen", sondern: Klare Eskalationsregeln, Pflichtfelder, Vier-Augen-Prinzip bei kritischen Outputs.
Für die Compliance-Sicht entscheidend: Dokumentieren Sie diese Eskalationsregeln. Sobald Sie nachweisen können, dass ein Mensch eine kritische KI-Ausgabe vor Veröffentlichung prüfen muss, sind Sie in einer ganz anderen Risikokategorie als Wettbewerber, die das nicht regeln.
6. Welcher Hebel für welchen Use Case? Eine Entscheidungshilfe
| Use Case | Wichtigster Hebel | Sinnvolle Ergänzungen | Was Sie weglassen können |
|---|---|---|---|
| Interne Wissenssuche („Was steht in unserer Dokumentation?") | RAG mit Quellen | Citation Grounding, Multi-Modell-Routing | Reasoning-Modus, Self-Consistency |
| Externer Kunden-Chatbot | Guardrails & Output-Validierung | RAG, Citation, Eskalation an Mensch | Reasoning-Modus (zu teuer pro Request) |
| Daten- & Excel-Analyse | Tool Use (Code-Interpreter, SQL) | Audit-Logs, Self-Consistency | RAG (Daten kommen aus Tools, nicht Dokumenten) |
| Vertragsanalyse / Recht | Human-in-the-Loop, dokumentiert | RAG, CoVe, Multi-Modell-Voting | Reine LLM-Antwort ohne Quellen |
| Code-Generierung | Tool Use (Test-Runner, Linter) | Multi-Modell-Routing, Slopsquatting-Check | Citation Grounding |
| Strategiepapiere & Recherche | Reasoning + Web-Tool-Use | Citation Grounding, Self-Consistency | Schnellster günstiger Mode |
Slopsquatting – die unterschätzte Code-Halluzination
Eine Studie der Universitäten Texas San Antonio, Oklahoma und Virginia Tech (2024) hat 16 Sprachmodelle getestet, darunter Claude, ChatGPT-4 und DeepSeek: Bei 576.000 analysierten Code-Samples lag die Halluzinationsrate bei 5,2 % für kommerzielle Modelle und 21,7 % für Open-Source-Modelle. 43 % der halluzinierten Paketnamen erschienen in mehreren Wiederholungsläufen erneut – also kein Zufall.
Das ist Halluzination mit Sicherheitsdimension: Angreifer registrieren genau diese halluzinierten Paketnamen vor und schleusen Schadcode ein. Wer Coding-Assistenten produktiv einsetzt, braucht zwingend einen Paket-Audit-Schritt (z. B. Aikido, Trend Micro, OSS Review Toolkit) in der Pipeline.
7. Praxis-Checkliste: Halluzinations-Governance in 14 Schritten
Was Sie in den nächsten 90 Tagen tun sollten
-
Inventur: Welche KI-Tools sind heute im Einsatz – auch inoffiziell? Siehe Shadow-AI-Risiko.
-
Klassifizierung: Welche Use Cases sind intern, welche extern? Welche sind „nice to have", welche entscheidungsrelevant?
-
Risiko-Mapping: Pro Use Case dokumentieren, welche Halluzinationsarten relevant sind (faktisch, Kontext, Selbstüberschätzung).
-
Quellen-Pflicht: Festlegen, für welche externe Kommunikation Antworten ohne Quelle nicht erlaubt sind.
-
Eskalationsregeln: Welche Outputs gehen automatisch durch, welche brauchen Vier-Augen-Prinzip?
-
RAG einführen: Mindestens für die drei wichtigsten Wissensquellen (z. B. Confluence, SharePoint, ERP).
-
Multi-Modell-Strategie: Sicherstellen, dass mindestens zwei Modellfamilien (z. B. OpenAI + Anthropic) ohne Migrationskosten getauscht werden können.
-
Guardrails: Für externe Bots NeMo Guardrails oder vergleichbare Lösung evaluieren.
-
Mitarbeiter-Schulung: Pflicht-Module zu Halluzinationen, Quellenprüfung und „Wann eskalieren?". Erfüllt automatisch einen Teil von Art. 4 EU AI Act.
-
Audit-Logs: Welcher User hat welche KI-Antwort wann erhalten und freigegeben? 24 Monate Aufbewahrung sind ein guter Default.
-
Red Teaming: Vierteljährlich Stresstests: Bringen Sie Ihren Chatbot dazu, etwas Falsches zu sagen. Beheben Sie es.
-
Metriken: Halluzinationen messbar machen – z. B. Stichproben-Audits durch Fachbereich (mindestens 50 Antworten/Monat).
-
Vertragliche Absicherung: Im AV-Vertrag mit KI-Anbietern klären, wer wofür haftet. Siehe AVV für KI-Dienste.
-
Regelmäßige Modellbewertung: Wenn ein neues Modell rauskommt (Claude Opus 4.8, GPT-5.6, Gemini 3.2 …): einen Tag „Re-Benchmark" einplanen. Versionen verändern sich messbar.
8. Wie Plotdesk diese sieben Hebel kombiniert
Plotdesk wurde als deutsche, DSGVO-konforme KI-Plattform gebaut, um genau das Problem zu lösen, das oben beschrieben wurde: Unternehmen, die KI verantwortungsvoll einsetzen wollen, ohne für jede Halluzinationsschutzmaßnahme ein eigenes Tool zu kaufen.
Konkret bedeutet das:
Native Multi-Modell-Strategie
Aktuelle Modelle wie Claude Opus 4.7, GPT-5.5 und Gemini 3 Pro sind über eine einheitliche Oberfläche und API ansprechbar. Halluziniert eine Modellversion, wird auf eine andere umgeschaltet – ohne Code-Änderung.
Files-Feature mit RAG-Logik
Tausende Dokumente (PDF, Word, Excel) lassen sich mit eigenem OCR und Indexierung anbinden. Antworten enthalten standardmäßig Quellenangaben mit Verlinkung auf den Originalabschnitt.
Instructions auf drei Ebenen
Organisations-, Team- und Unterteam-spezifische Vorgaben („Antworte nie ohne Quelle aus unserem Wiki") werden hierarchisch vererbt. Das ist Halluzinations-Prävention durch Design.
Reports & Audit
Jede Anfrage ist protokolliert und auswertbar. Stichproben-Audits, Eskalationen und Schulungslücken werden sichtbar – Voraussetzung für saubere AI-Literacy-Dokumentation nach Art. 4 EU AI Act.
Plotdesk ersetzt also nicht die Modelle, sondern die Governance-Schicht darüber. Das ist auch der Hauptunterschied zu ChatGPT Enterprise oder Microsoft Copilot, die für die breite Masse konzipiert sind. Wer einen detaillierten Vergleich sucht: Plotdesk vs. ChatGPT Enterprise.
9. Häufige Fragen aus der Praxis
Werden Halluzinationen mit jeder Modellgeneration weniger?
Nein, das ist ein verbreiteter Irrtum. OpenAIs eigene Daten zeigen, dass Reasoning-Modelle wie o3 und o4-mini auf PersonQA mehr halluzinieren als das Vorgängermodell o1 (33 % und 48 % vs. 16 %). Größere Kontextfenster und mehr Denken bedeuten nicht automatisch mehr Wahrheit, sondern oft nur mehr Behauptungen pro Antwort.
Reicht ein gut formulierter Prompt aus, um Halluzinationen zu vermeiden?
Nein. Prompt Engineering reduziert das Risiko spürbar, eliminiert es aber nicht. Studien zeigen, dass strukturelle Hebel (RAG, Tool Use, CoVe) deutlich wirkungsvoller sind als reine Prompt-Optimierung. Beides zusammen ist der Goldstandard – mehr dazu im Artikel Prompt Engineering im Unternehmen.
Was passiert konkret, wenn unsere KI eine falsche Aussage über einen Kunden trifft?
Im deutschen Recht haftet der Betreiber. Der LG-Hamburg-Beschluss vom 23.09.2025 (Az. 324 O 461/25) hat das im Fall einer KI-Aussage über eine NGO ausdrücklich klargestellt. Disclaimer wie „This is AI-generated" entlasten nicht. Bei Verstoß gegen die einstweilige Verfügung drohte X.AI dort ein Ordnungsgeld von bis zu 250.000 € pro Verstoß.
Müssen kleine Unternehmen sich überhaupt um Halluzinationen kümmern?
Ja. Anders als bei einigen DSGVO-Pflichten kennt Artikel 4 EU AI Act (AI Literacy) keine Bagatellgrenze. Sobald Sie KI einsetzen, sind Sie verpflichtet, Ihre Mitarbeiter „nach besten Kräften" zu befähigen. Halluzinations-Bewusstsein gehört zu dieser Befähigung – und es ist auch wirtschaftlich klug, weil ein einziger PR-Vorfall wie bei DPD oder Air Canada teurer ist als ein Schulungsprogramm.
Welches Modell halluziniert am wenigsten?
Das hängt vom Anwendungsfall ab und ändert sich mit jeder Modellversion. Auf der Vectara Hallucination-Leaderboard-Methodik (Zusammenfassung von Dokumenten) führten zuletzt verschiedene Modelle aus der GPT-5- und Gemini-2.5-Familie mit Raten unter 4 %. Für Unternehmen ist die richtige Antwort nie „das eine beste Modell", sondern eine Multi-Modell-Strategie mit klar definierten Use-Case-Zuweisungen.
Brauchen wir wirklich einen separaten Guardrails-Layer wie NeMo?
Wenn Sie KI in externen Kanälen (Chatbot, automatische E-Mails, Self-Service-Portal) einsetzen: ja. Für rein interne Anwendungen mit geschulten Nutzern reicht meist RAG plus klare Quellen-Pflicht plus stichprobenartige Audits. Die Faustregel: Je weiter die KI-Ausgabe vom Auge eines verantwortlichen Mitarbeiters entfernt ist, desto härter müssen die technischen Guardrails sein.
Wie messen wir Halluzinationen messbar in unserem Betrieb?
Drei bewährte Wege: (1) Monatliche Stichproben-Audits durch Fachbereich – z. B. 50 Antworten pro Use Case, mit fünf Kategorien (richtig / leicht ungenau / faktisch falsch / Quellenfehler / Halluzination im Tool-Use). (2) Nutzer-Feedback-Button („War diese Antwort korrekt?") in der Plattform. (3) Synthetische Test-Suiten – also feste Fragen mit bekannten Antworten, die regelmäßig wieder gegen die KI laufen, sobald sich das Modell ändert.
10. Fazit: Halluzinationen sind ein Management-Thema, kein Modellthema
Wer 2026 noch wartet, bis „die KI von selbst aufhört zu halluzinieren", wird lange warten. Die Daten – PersonQA, Charlotin-Datenbank, LG Hamburg – zeigen das Gegenteil: Mit besseren Modellen verändert sich die Art der Halluzinationen, nicht ihre Existenz. Was sich verändern lässt, ist Ihre Reaktion darauf:
- Sie können RAG einführen, statt Modelle aus dem Gedächtnis antworten zu lassen.
- Sie können Quellen-Pflicht durchsetzen, statt auf Vertrauen zu setzen.
- Sie können Multi-Modell denken, statt sich an einen Anbieter zu binden.
- Sie können Ihre Mitarbeiter schulen, statt Bürokratie zu produzieren.
- Sie können Audits etablieren, bevor das Gericht sie verlangt.
Genau das ist der Unterschied zwischen Unternehmen, die KI 2026 zum Wettbewerbsvorteil machen, und denen, die in zwei Jahren erklären müssen, warum ihr Chatbot etwas Falsches gesagt hat.
Wenn Sie für Ihr Unternehmen einen konkreten Fahrplan brauchen: Unsere KI-Workshops sind genau auf diese Frage zugeschnitten – inklusive Live-Demo, Use-Case-Sammlung und einer Halluzinations-Risikoanalyse für Ihre konkrete Branche.


