
Zwei Jahre lang konnten Unternehmen die KI-Rechnung als Innovationsbudget abbuchen. 2026 ist damit vorbei. Der State-of-FinOps-2026-Report der FinOps Foundation – basierend auf 1.192 Praktikerantworten und kumuliert über 83 Mrd. USD jährliches Cloud-Spend – zeigt, dass 98 % der FinOps-Teams mittlerweile KI-Kosten aktiv managen. Vor zwei Jahren waren es 31 %. „AI Cost Management" ist laut der Linux Foundation die meistgesuchte neue Kompetenz in der Disziplin – noch vor klassischer Cloud-Optimierung.
Parallel dazu prognostiziert Gartner für 2027, dass mehr als 40 % der Agentic-AI-Projekte abgebrochen werden – primär wegen unklarer Wirtschaftlichkeit und steigender Kosten. Die FinOps Foundation verortet 80–90 % der laufenden KI-Ausgaben in der Inferenz (nicht im Training), bei einer realen GPU-Auslastung im Betrieb von oft nur 15–30 %. CIO.inc berichtet – unter Berufung auf den Gartner Hype Cycle for Agentic AI 2026 – dass die durchschnittliche KI-Rechnung großer Unternehmen von rund 1,2 Mio. USD (2024) auf rund 7 Mio. USD (2026) gestiegen ist.
Für deutsche Mittelständler, die nach Bitkom 2026 zu 41 % aktiv KI einsetzen, wird die Frage damit konkret: Wie steuert man Token-Kosten, Inferenz-Workloads und Agenten-Loops so, dass am Ende ein nachweisbarer ROI steht – statt einer „Sticker-Shock"-Quartalsrechnung? Dieser Leitfaden bringt die Antworten – mit Quellen, ohne Buzzword-Bingo, und mit einem 90-Tage-Plan für die DACH-Realität.
Die wichtigsten Zahlen auf einen Blick
Status quo 2026:
- 98 % der FinOps-Teams managen KI-Spend (vs. 31 % in 2024, 63 % in 2025) – State of FinOps 2026 Report der FinOps Foundation
- Über 40 % der Agentic-AI-Projekte werden laut Gartner-Prognose bis Ende 2027 abgebrochen – primär wegen unklarer Wirtschaftlichkeit und Kostenkontrolle
- 80–90 % der laufenden KI-Kosten entstehen in der Inferenz, nicht im Training – FinOps Foundation, Working Paper „Optimizing GenAI Usage"
- 15–30 % GPU-Auslastung im laufenden KI-Betrieb (gleiche Quelle)
- Anteil GPU-intensiver Workloads am Cloud-Budget bei KI-aktiven Unternehmen: 4 % (2023) → 18 % (2026) – Flexera 2026 State of the Cloud Report
- Durchschnittliche KI-Rechnung großer Unternehmen: rund 1,2 Mio. USD (2024) → rund 7 Mio. USD (2026) – CIO.inc unter Berufung auf den Gartner Hype Cycle for Agentic AI 2026
Was die größten Hebel sind:
- Prompt Caching: bis zu 90 % Kostenreduktion auf wiederkehrende Input-Tokens – Anthropic, OpenAI
- Batch API: pauschal 50 % Discount für asynchrone Workloads bei Anthropic und OpenAI
- Kombiniert: bis zu 95 % weniger Kosten auf cached Batch-Reads
- Modell-Routing: 60–95 % Einsparung bei Einsatz kleinerer Modelle für einfache Aufgaben
- Semantic Cache: 30–60 % weniger LLM-Calls in produktiven Workflows
Was 2026 in Deutschland gilt: Ab dem 2. August 2026 greifen weitere Stufen der EU-KI-Verordnung (u. a. Durchsetzung der GPAI-Pflichten und große Teile der Transparenzpflichten nach Art. 50). Die ursprünglich ebenfalls für diesen Stichtag vorgesehenen Hochrisiko-Pflichten nach Anhang III wurden mit der politischen Einigung zum „Digital Omnibus" vom 7. Mai 2026 voraussichtlich auf den 2. Dezember 2027 verschoben (Anhang I: 2. August 2028). In Deutschland hat das Bundeskabinett am 11. Februar 2026 den Regierungsentwurf des KI-MIG (KI-Marktüberwachungs- und Innovationsförderungsgesetz) beschlossen, der die Bundesnetzagentur als zentrale Marktüberwachungsbehörde und das KoKIVO (Koordinierungs- und Kompetenzzentrum für die KI-Verordnung) mit einem KI-Service-Desk vorsieht; das Gesetz durchläuft Stand Mai 2026 das parlamentarische Verfahren. Eine Pflicht zur expliziten KI-Kostenkontrolle ergibt sich aus alldem nicht direkt – aber wer ein KI-Risikomanagement nach Art. 9 KI-VO aufsetzt, kommt um eine belastbare Cost-Attribution faktisch nicht herum.
1. Was FinOps für KI wirklich ist – und was es nicht ist
FinOps ist 2026 in vielen mittelständischen IT-Abteilungen noch ein Schatten-Begriff. Die FinOps Foundation definiert die Disziplin als operatives Framework, in dem Engineering, Finance und Business gemeinsam Cloud- und Technologie-Ausgaben steuern – mit dem Ziel, technologische Investitionen wirtschaftlich abzubilden und in Echtzeit nachzujustieren.
FinOps für KI ist die Erweiterung dieser Logik auf nutzungsbasierte KI-Workloads. Das klingt simpel, hat es technisch aber in sich: Eine klassische SaaS-Lizenz skaliert linear mit Sitzen, eine Cloud-Ressource mit Hardware-Klasse und Laufzeit. Token-basierte KI-Workloads skalieren nicht-linear – mit der Anzahl der Nutzer, der Länge ihrer Prompts, den Größe der RAG-Kontexte, der Anzahl der Tool-Calls eines Agenten und der Komplexität jeder Antwort.
Drei klare Abgrenzungen, weil die Begriffe regelmäßig verwechselt werden:
FinOps ≠ TCO-Analyse
Eine TCO-Berechnung ist eine statische Investitionsentscheidung. FinOps ist ein laufendes Steuerungsmodell mit Telemetrie, Allokation und Forecast – pro Tag, nicht pro Geschäftsjahr.
FinOps ≠ Procurement
Einkauf verhandelt Rabatte pro Vertragsperiode. FinOps verhandelt Architektur-Entscheidungen pro Sprint – z. B. „darf dieser Workflow auf das Frontier-Modell oder reicht ein Small-Model".
FinOps ≠ DevOps-Kostenkontrolle
Klassische DevOps-Tools messen CPU/Memory pro Container. FinOps für KI braucht Token-Telemetrie pro Prompt, pro User, pro Use Case – das liefern Standard-APM-Tools nicht.
In der Praxis bedeutet FinOps für KI drei zusammenspielende Schichten: Telemetrie (jeder LLM-Call wird mit Input-/Output-/Cache-Tokens und Tags geloggt), Allokation (Kosten werden Use Cases, Teams oder Endkunden zugeordnet) und Optimierung (Modell-Wahl, Caching, Routing, Limits werden datenbasiert angepasst). Wer eine dieser Schichten überspringt, optimiert im Dunkeln.
2. Warum 2026 der Kipppunkt ist
Drei strukturelle Veränderungen lassen FinOps für KI 2026 vom Nischenthema zur Vorstandsfrage werden.
Erstens: Die Universalität. Vor zwei Jahren managten 31 % der FinOps-Teams überhaupt KI-Spend, vor einem Jahr 63 %, heute 98 %. Diese Adoption ging schneller, als Tooling, Governance und Skills entstehen konnten – die Linux Foundation formuliert das so: „managed before tooling and frameworks were in place".
Zweitens: Die Verschiebung von Training zu Inferenz. Modelle werden zentral trainiert, aber dezentral konsumiert. Jeder zusätzliche aktive Nutzer, jeder längere Prompt, jeder zusätzliche Tool-Call eines Agenten lädt die laufende Inferenz-Rechnung neu. Die FinOps Foundation verortet 80–90 % der KI-Ausgaben in der Inferenz – mit GPU-Auslastung im laufenden Betrieb von häufig nur 15–30 %.
Drittens: Die agentische Eskalation. Ein klassischer Chatbot ruft das Modell ein- bis zweimal pro User-Turn. Ein autonomer Agent durchläuft Planungs-, Tool- und Reflexionsschleifen – ein einziger „intelligenter" Vorgang kann laut CIO.inc / Gartner Hype Cycle 2026 100 bis 1.000 Mal mehr Token verbrauchen als ein Standard-Chat. Wer 2025 nur Copilot ausgerollt hatte und 2026 erste Agenten-Workflows in Produktion bringt, sieht den Sprung sofort auf der Rechnung.
| Kennzahl | 2024 | 2026 | Quelle |
|---|---|---|---|
| FinOps-Teams mit KI-Spend-Mandat | 31 % | 98 % | FinOps Foundation |
| Anteil KI an Cloud-Budget (KI-affine Unternehmen) | 4 % | 18 % | FinOps Foundation |
| Durchschnittliche KI-Rechnung großer Unternehmen / Jahr | ~1,2 Mio. USD | ~7 Mio. USD | CIO.inc unter Berufung auf Gartner Hype Cycle 2026 |
| Agentic-AI-Projekte mit Abbruch-Prognose bis 2027 | – | > 40 % | Gartner Prognose, Juni 2025 |
| Anteil Inferenz an KI-Gesamtkosten (TCO) | ~60–70 % | 80–90 % | FinOps Foundation Working Paper |
Was das für Sie heißt
Wenn Ihr Unternehmen 2025 noch primär „Lizenzen für ChatGPT Enterprise" oder „Copilot pro User" gekauft hat, war die KI-Rechnung kalkulierbar. Wer 2026 produktive Workflows mit eigenen Prompts, RAG, Agenten oder Multi-Modell-Strategien ausrollt, sieht die Rechnung nicht-linear nach oben gehen. Die Frage ist nicht ob ein FinOps-Setup nötig wird – sondern wie früh Sie es aufsetzen, bevor der CFO die Quartalsrechnung sieht.
3. Die vier typischen Kostenfallen – und woher sie kommen
In der Praxis lassen sich die Budget-Sprenger 2026 fast vollständig auf vier Muster zurückführen. Wer keinen davon kennt, baut sich blind in genau diese Falle hinein.
Falle 1 – Output-Tokens werden unterschätzt. Bei den großen Frontier-Modellen ist der Preis pro Output-Token typischerweise das Fünf- bis Achtfache des Input-Preises. Bei GPT-5 von OpenAI liegt Input bei 1,25 USD/M Tokens, Output bei 10,00 USD/M Tokens – Faktor 8. Bei Claude Opus 4.7 ist es 5 USD vs. 25 USD – Faktor 5. Reasoning-Modelle wie Gemini 3 Pro zählen die internen Thinking-Tokens komplett zum Output – ein einzelner komplexer Prompt kann 4.500 Output-Tokens generieren, von denen nur 500 für den Nutzer sichtbar sind.
Falle 2 – RAG-Kontext bläht sich auf. Eine schlecht dimensionierte RAG-Pipeline sendet pro Frage 10–20× so viel Kontext wie nötig – meist, weil der Embedding-Retriever konservativ konfiguriert ist oder weil Chunk-Größen nie nachjustiert wurden. In großen Wissensdatenbanken hängt das Budget direkt am Retrieval-Tuning.
Falle 3 – Agent-Loops ohne Abbruchkriterium. Ein autonomer Agent darf nicht „bis zur perfekten Antwort" weiteriterieren. Ohne harte max_iterations, Token-Budgets pro Konversation und Eskalationspfad in einen menschlichen Workflow läuft die Rechnung weiter, auch wenn der Output längst gut genug wäre.
Falle 4 – Shadow AI als nicht zugeordnete Kosten. Selbst wenn ein Unternehmen eine zentrale Plattform betreibt, laufen oft 20–40 % der KI-Nutzung über persönliche Accounts oder dezentrale Tool-Lizenzen. Diese Kosten tauchen verteilt im Spesenabrechnungssystem auf – nie konsolidiert. Shadow AI ist 2026 sowohl ein Security- als auch ein FinOps-Problem.
Antimuster: „Wir bauen erst, messen später"
Engineering-Teams setzen produktive Workflows ohne Token-Telemetrie auf. Erste Sichtbarkeit kommt mit der dritten oder vierten Monatsrechnung – dann ist der Architektur-Pfad schon eingefahren.
Typische Folge: Quartals-Reforecast +120 %, Notbremsung mit Token-Limits, Frust bei Power-Usern.
Erfolgsmuster: „Tag-Zero-Telemetrie"
Jeder LLM-Call wird vom ersten Prototyp an mit User, Use Case, Modell und Token-Counter geloggt. Budget-Alerts sind vor dem Go-Live aktiv.
Typische Folge: Frühe Architektur-Korrekturen (Caching, Modell-Mix) verhindern den Knall im Q2 – statt ihn zu reparieren.
4. Modell-Pricing 2026 im direkten Vergleich
Der wichtigste Hebel bleibt die richtige Modell-Wahl pro Aufgabe. Die folgende Tabelle bündelt die offiziell publizierten Preise (Stand Mai 2026) der vier relevanten Anbieter für die DACH-Region – Frontier-Modelle und ihre kleineren Geschwister. Alle Werte beziehen sich auf USD pro 1 Million Tokens. Cache-Pricing variiert pro Anbieter erheblich – das ist der zweite Hebel.
| Modell | Input | Cached Input | Output | Hinweis |
|---|---|---|---|---|
| OpenAI GPT-5 | 1,25 $ | 0,125 $ (−90 %) | 10,00 $ | 400K Kontext, Auto-Caching ab 1024 Tokens |
| OpenAI GPT-5.4 | 2,50 $ | 0,25 $ (−90 %) | 15,00 $ | Reasoning-Variante |
| Anthropic Claude Haiku 4.5 | 1,00 $ | 0,10 $ (−90 %) | 5,00 $ | Cache-Control explizit setzen |
| Anthropic Claude Sonnet 4.6 | 3,00 $ | 0,30 $ (−90 %) | 15,00 $ | Standard für Production-Workloads |
| Anthropic Claude Opus 4.7 | 5,00 $ | 0,50 $ (−90 %) | 25,00 $ | Reasoning + Extended Thinking |
| Google Gemini 3 Pro (≤200K) | 2,00 $ | 0,20 $ (−90 %) | 12,00 $ | Output inkl. Thinking-Tokens, + Storage 4,50 $/M·h |
| Google Gemini 3 Pro (>200K) | 4,00 $ | 0,40 $ (−90 %) | 18,00 $ | Long-Context-Rate auf gesamte Anfrage |
Stand Mai 2026, USD pro 1 Mio. Tokens. Quellen: OpenAI, Anthropic, Google Cloud. Preise können sich kurzfristig ändern – immer am Anbieter-Frontend verifizieren.
Drei Beobachtungen, die für die Architekturentscheidung 2026 wichtig sind:
Beobachtung 1: Der Preisabstand zwischen Small und Large Models liegt bei Faktor 4–10. Ein Klassifizierungs-Task auf Claude Haiku 4.5 kostet etwa 20 % dessen, was er auf Claude Opus 4.7 kosten würde – bei oft vergleichbarer Qualität für strukturierte Aufgaben. Pexon Consulting berichtet aus eigener Praxis, dass intelligente Modell-Auswahl bei einem Azure-OpenAI-Kunden die Monatsrechnung um eine deutliche Größenordnung gesenkt hat – allein durch Routing und konsequentes Caching.
Beobachtung 2: Cached-Input-Pricing ist 2026 der zweite große Hebel. Bei OpenAI ist die Anwendung automatisch ab 1.024 Tokens Präfix; bei Anthropic muss cache_control aktiv gesetzt werden, dafür sind die Discounts mit bis zu 90 % maximal. Wer Long-Context-RAG ohne Caching betreibt, zahlt strukturell zu viel.
Beobachtung 3: Output-Tokens werden bei Reasoning-Modellen unsichtbar teurer. Gemini 3 Pro zählt interne Thinking-Tokens explizit zum Output. Bei Thinking Models ist die Rechnung nicht „Eingabe + Antwort", sondern „Eingabe + Antwort + ungeschnittener Modell-Monolog". Das ist je nach Aufgabe richtig investiert – oder reines Geld-Verbrennen.
5. Die sieben Hebel, die in der Praxis wirken
Wer FinOps für KI 2026 ernst nimmt, optimiert nicht an einzelnen Stellschrauben, sondern systematisch entlang der gesamten Architektur. Aus der gut dokumentierten Praxis der letzten 18 Monate kristallisieren sich sieben Hebel heraus – sortiert nach typischer Wirkung pro Aufwand.
Prompt Caching aktiv nutzen — bis −90 % Input-Kosten
System-Prompts, Few-Shot-Beispiele und wiederkehrende Kontext-Dokumente werden gecached. Anthropic Prompt Caching ist seit Dezember 2024 GA und reduziert Cache-Reads auf 10 % des Base-Preises. OpenAI cached automatisch ab 1.024 Tokens. Gemini bietet implizites und explizites Caching mit ≥75 % Discount. Voraussetzung: gleicher Präfix in vielen Aufrufen. Aufwand niedrig, Wirkung hoch.
Batch API für asynchrone Workloads — pauschal −50 %
Für alle Workloads, die nicht in Sekunden, sondern in Stunden Latenz toleriert werden (Nachtläufe, Massendokumentenanalyse, Berichts-Generierung), bieten Anthropic und OpenAI eine Batch API mit pauschal 50 % Rabatt auf alle Tokens. Kombiniert mit Caching: bis zu 95 % Reduktion. Aufwand mittel (Architektur muss asynchron werden), Wirkung sehr hoch für die richtigen Use Cases.
Multi-Modell-Routing nach Task-Komplexität — 60–95 % je nach Task-Mix
Klassifikation, Extraktion, einfache Q&A → Small Model (Haiku 4.5, GPT-5-mini, Gemini Flash). Komplexe Synthese, mehrschrittige Logik → Frontier Model. Eine konservative Multi-Modell-Strategie spart laut Industriebenchmarks 60–95 % gegenüber „alles auf Opus". Aufwand mittel (Router + Eval-Set), Wirkung sehr hoch.
Semantic Cache vor das Modell — 30–60 % weniger LLM-Calls (wiederholungsstarke Workloads)
Ähnliche Anfragen (FAQ-artige Kundenservice-Fragen, wiederkehrende Reports, Klassifikation) müssen nicht jedes Mal das Modell beanspruchen. Semantic-Cache-Layer (Redis Vector, LangChain Cache, MemGPT) reduzieren in wiederholungsstarken Workloads typisch 30–60 % der Calls vollständig. Bei offenem Dialog, RAG und Code-Generation deutlich weniger (10–25 %). Aufwand mittel, Wirkung hoch bei wiederholungslastigen Use Cases.
Output-Limits und strukturierte Antworten — 20–40 % Output-Kosten
`max_tokens` strikt setzen, JSON-Schemas statt Freitext, „Antworte in 3 Sätzen"-Prompts. Output-Tokens sind 5–10× teurer als Input – jede unnötige Erklärung kostet konkret Geld. Aufwand niedrig, Wirkung solide.
RAG-Kontext-Hygiene — 30–70 % Input-Volumen
Chunk-Größen passend zur Frage-Komplexität, Re-Ranking nach Relevanz, dynamisches Top-K (nicht starr 20 Dokumente pro Anfrage). Eine schlecht dimensionierte RAG-Pipeline ist der Hauptgrund, warum Wissensagenten überraschend teuer werden. Aufwand hoch (Evaluations-Setup), Wirkung sehr hoch.
Agenten-Budgets pro Konversation — Schutz vor Runaway-Kosten
Jeder autonome Agent läuft mit hartem Token-Budget pro Session, max_iterations pro Plan-Loop und definiertem Eskalationspfad in einen menschlichen Workflow. Ohne diesen Schutz sind 100–1.000× Token-Multiplikator pro „intelligentem" Vorgang real – und der nächste Quartalsbericht ist nicht mehr lustig. Aufwand niedrig (Limit setzen), Wirkung kritisch (Reputations- und Budget-Schutz).
6. Reifegradmodell – wo steht Ihr Unternehmen?
Die FinOps Foundation arbeitet mit einem dreistufigen Reifegradmodell (Crawl → Walk → Run). Für KI-spezifische Kostensteuerung lässt sich daraus pragmatisch eine vier-stufige Ableitung formen, die in der DACH-Realität gut funktioniert. Ehrliche Standortbestimmung ist der erste Schritt – die meisten deutschen Mittelständler sind 2026 noch auf Stufe 1 oder 2.
| Stufe | Charakteristik | Was fehlt | Nächster Schritt |
|---|---|---|---|
| 1 · Token-blind | Pauschale Lizenz pro User, keine Telemetrie pro Workflow, KI-Rechnung kommt als Quartalsschock | Sichtbarkeit, Allokation, Verantwortung | Token-Tracking pro Use Case einführen |
| 2 · Token-aware | Plattform loggt Calls, Monatsreporting existiert, aber keine Architektur-Optimierung | Caching, Modell-Routing, Limits | Hebel 1–3 (Caching, Batch, Routing) ausrollen |
| 3 · Token-optimized | Caching aktiv, intelligentes Routing, Budgets pro Use Case, Cost-Forecast pro Sprint | Showback/Chargeback an Business-Units, Eval-getriebene Modell-Wechsel | FinOps-Rolle im Unternehmen verankern |
| 4 · Token-strategic | KI-Kosten sind Business-KPI pro Produkt, Self-Funding durch Optimierung, kontinuierliche Architektur-Anpassung | Das Niveau halten – Modelle und Preise ändern sich quartalsweise | Quartalsweise Re-Architektur-Reviews |
Der typische Sprung, an dem Unternehmen scheitern, ist von Stufe 2 zu Stufe 3. Bis dahin reicht es, ein Reporting zu haben. Ab Stufe 3 muss die Architektur datengetrieben angepasst werden – das verlangt einen klaren Owner, ein Eval-Set pro Use Case und eine Engineering-Disziplin, Cost-Forecasts in jeden Pull-Request einzubauen. Wer diese Brücke nicht baut, hat Telemetrie, aber keine Wirkung.
7. Die fünf KPIs, die jedes FinOps-für-KI-Setup braucht
Vorstand und CFO interessieren sich nicht für Token-Counts – sie interessieren sich für Wirtschaftlichkeit. Die richtige Übersetzung ist eine kompakte Kennzahlen-Liste, die jeder Sprint-Owner versteht und jede CFO-Folie übersteht.
CFO-Reporting in einem Satz
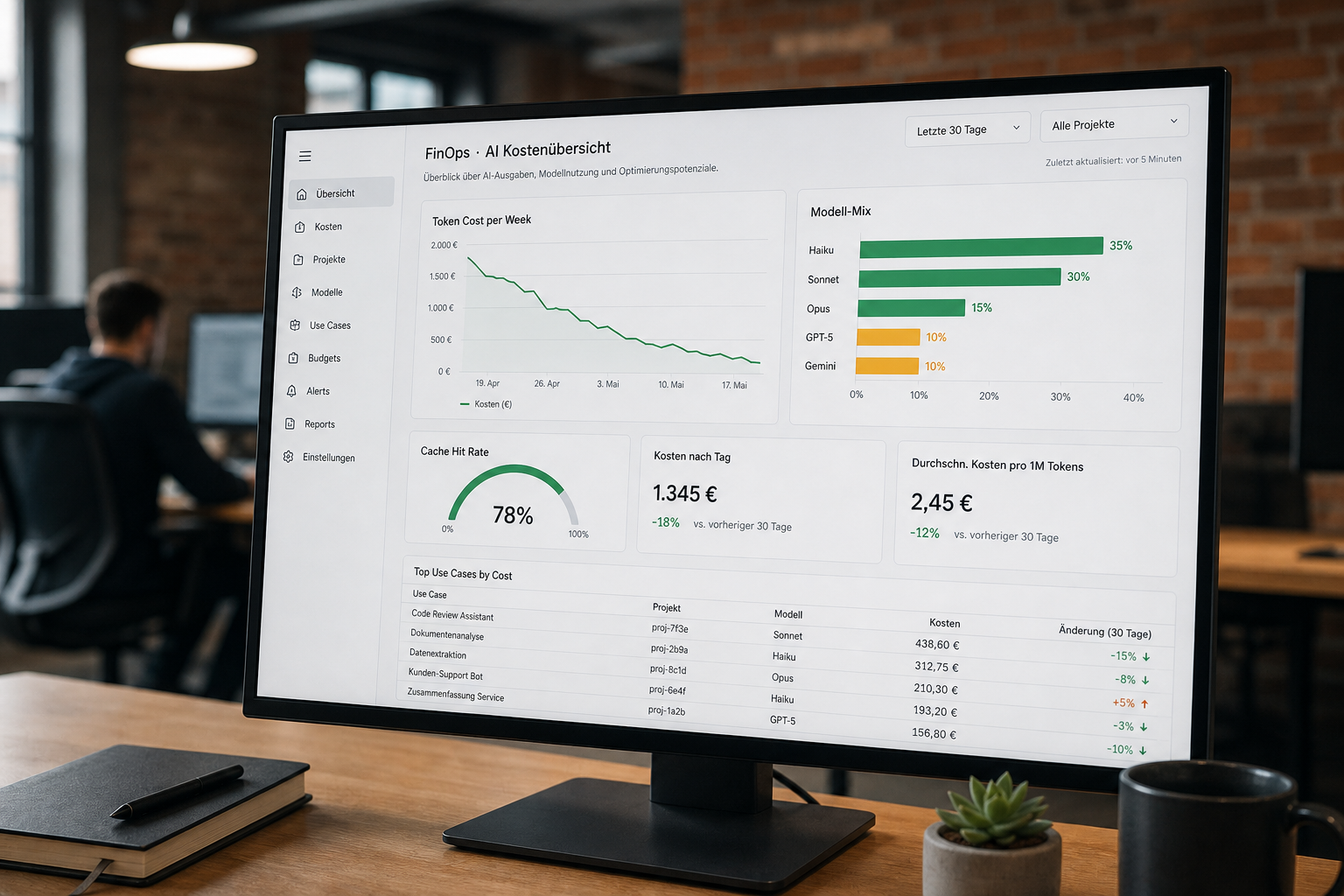
„Wir bearbeiten Use Case X heute mit 0,42 € pro Vorgang statt 3,80 € pro Vorgang (Mensch) bei einer Cache-Hit-Rate von 78 % und einer Forecast-Genauigkeit von 92 %." Das ist die Sprache, die in Vorstands-Briefings funktioniert – nicht „wir haben 4,2 Millionen Tokens verbrannt".
8. Der 90-Tage-Plan für deutsche Mittelständler
Wer 2026 ein FinOps-für-KI-Setup aufbaut, sollte sich nicht in einem 18-Monats-Programm verlieren. Drei klare Sprints à 30 Tage führen vom unkontrollierten Status quo zu einer messbaren Kostensteuerung. Wichtig: Der Plan ist eine Architektur-Disziplin, kein Tool-Kauf – die meisten Hebel funktionieren mit Open-Source-Komponenten oder mit den nativen Features der KI-Plattform.
Sichtbarkeit schaffen
- • Token-Telemetrie pro Call aktivieren (LangFuse, OpenTelemetry oder Plattform-native)
- • Tags pro User, Team, Use Case, Modell
- • Baseline-Dashboard: Top-10 Use Cases nach Kosten
- • Hard Limits pro Service-Account
- • Erste Schadensanalyse: Wo geht das meiste Geld hin?
Quick Wins umsetzen
- • Prompt Caching für alle Top-3 Use Cases aktivieren
- • Batch API für Massen-Workloads umstellen
- • Output-Limits in allen System-Prompts
- • Modell-Routing als Erst-Linie (Small Model first, Frontier nur bei Bedarf)
- • Budget-Alerts an Slack/Teams
Disziplin verankern
- • Cost-Forecast in jeden PR der KI-Workflows
- • Quartalsweise Architektur-Review mit Eval-Set
- • Showback/Chargeback an Business-Units
- • FinOps-für-KI-Owner benennen (Brücke Engineering ↔ Finance)
- • Erste CFO-Folie mit Cost-per-Resolution
In dieser Reihenfolge sind in dokumentierten Praxisberichten 20–40 % Kostenreduktion im ersten Quartal realistisch (Pexon-Consulting-Bericht 2026 zu einem Azure-OpenAI-Kunden mit aktivem Token-Tracking via Langfuse) – ohne dass eine produktive Funktion eingeschränkt wird. Die genaue Größenordnung hängt vom Ausgangszustand ab; wer die Telemetrie überspringt und direkt mit Sprint 2 startet, optimiert blind und sieht den Effekt nicht in den eigenen Zahlen.
9. Was der EU AI Act ab August 2026 dazu sagt
Strenggenommen verlangt die EU-KI-Verordnung keine Kostenkontrolle. Aber: Wer ein Risikomanagement nach Art. 9 KI-VO für ein Hochrisiko-System aufsetzt, kommt um eine belastbare Cost-Attribution pro KI-System faktisch nicht herum – jedes produktive System muss klar abgegrenzt, dokumentiert und über den gesamten Lebenszyklus mit Ressourcendaten hinterlegt sein.
Zur Zeitlinie: Ab dem 2. August 2026 greifen die nächsten Stufen der KI-Verordnung – insbesondere die Durchsetzung der GPAI-Pflichten und der größten Teile der Transparenzpflichten nach Art. 50 (Hinweis bei direkter KI-Interaktion, Deepfake-Kennzeichnung, Hinweis bei Emotionserkennung). Die ursprünglich ebenfalls für diesen Stichtag vorgesehenen Hochrisiko-Pflichten nach Anhang III wurden mit der politischen Einigung zum „Digital Omnibus" vom 7. Mai 2026 voraussichtlich auf den 2. Dezember 2027 verschoben; Anhang-I-Hochrisiko-Systeme (eingebettete Sicherheitskomponenten) auf den 2. August 2028. Die Watermarking-Pflicht nach Art. 50(2) verschiebt sich auf den 2. Dezember 2026.
In Deutschland hat das Bundeskabinett am 11. Februar 2026 den Regierungsentwurf des KI-MIG (KI-Marktüberwachungs- und Innovationsförderungsgesetz) beschlossen. Das Gesetz – Stand Mai 2026 im parlamentarischen Verfahren – benennt die Bundesnetzagentur als zentrale Marktüberwachungsbehörde und richtet das KoKIVO (Koordinierungs- und Kompetenzzentrum für die KI-Verordnung) ein, das u. a. einen KI-Service-Desk als zentrale Anlaufstelle für Unternehmen betreibt.
Wer also ohnehin ein KI-Beauftragten-Modell und eine KI-Richtlinie aufbaut, sollte die FinOps-Disziplin direkt in die Governance integrieren – nicht parallel. Cost-Owner und Compliance-Owner sollten dieselben Use-Case-IDs verwenden. Damit sparen sich die meisten Mittelständler eine zweite Inventarisierungs-Runde.
Pragmatische Empfehlung
Verankern Sie FinOps-für-KI nicht in einer neuen Stabsfunktion, sondern als Querschnittsdisziplin zwischen Plattform-Team (Telemetrie), Finance (Allokation und Forecast) und KI-Beauftragtem (Use-Case-Register und Risikoklassifikation). Ein einziges KI-Use-Case-Register – mit Cost-, Risk- und Compliance-Sicht – ist die effizienteste Architektur, gerade für Mittelständler ohne große Beratungs-Tagessätze.
10. Häufige Fehler in DACH-Implementierungen
Aus der dokumentierten Praxis der letzten 12 Monate lassen sich fünf wiederkehrende Fehler ableiten – jeder davon kostet mehrstellige Beträge, weil er den eigentlichen Hebel verdeckt.
Fehler 1 – „Erst rollen wir aus, dann messen wir"
Die häufigste Quelle für Quartals-Schocks. Wer Telemetrie nachrüstet, verliert die ersten Monate Architektur-Daten und kann nicht mehr rekonstruieren, wo das Geld hinging.
Fehler 2 – „Alles auf das Top-Modell"
Ein Engineering-Team picked Claude Opus 4.7 oder GPT-5.4, weil die Demos beeindrucken – und routet nie zurück. Resultat: 5–10× höhere Rechnung als bei einem differenzierten Modell-Mix, oft ohne messbar besseren Output.
Fehler 3 – Caching „später"
Prompt Caching wird als Optimierung in Sprint 8 eingeplant – tatsächlich ist es eine Architektur-Entscheidung in Sprint 1. Wer System-Prompts ohne Caching-Struktur baut, retrofittet später mit doppeltem Aufwand.
Fehler 4 – Agenten ohne Budget
Ein neuer Agent geht in Produktion ohne hartes Token-Budget pro Session. Beim ersten edge case läuft die Schleife bis zum Plattform-Limit – einzelne Konversationen können dreistellige Euro-Beträge kosten.
Fehler 5 – Reporting an die IT, nicht an den CFO
Kostenreports landen im wöchentlichen Engineering-Standup und werden dort als „Performance-Daten" behandelt. Der CFO bekommt sie nicht – bis die Rechnung kommt. Die State-of-FinOps-Daten zeigen, dass nur 8 % der FinOps-Teams an einen CFO berichten, 78 % an einen CIO/CTO. Das ist organisatorisch das größte Hindernis für ehrliche Steuerung.
11. Wie Plotdesk hier hilft
Plotdesk ist eine in Deutschland gehostete KI-Plattform, die FinOps-für-KI strukturell mitdenkt – statt als nachträglichen Add-on-Layer.
Multi-Modell aus einer Plattform. Auf Plotdesk laufen über 50 Modelle parallel – Frontier (GPT-5, Claude Opus 4.7, Gemini 3 Pro), Mid-Range (Sonnet, Haiku, Gemini Flash) und Open-Source-Optionen, gehostet in der EU. Intelligentes Routing pro Use Case ist nicht „Plus-Paket", sondern Standard. Hintergrund: unser eigener Artikel zur Multi-Modell-Strategie erklärt, warum Vendor-Lock-in 2026 das teuerste Architektur-Antipattern ist.
Cost-Reports nativ. Token-Tracking pro Nutzer, Team und Use Case ist auf Plotdesk Standard. Cache-Hits werden separat ausgewiesen, Modell-Mix ist live einsehbar, Budget-Alerts sind pro Team konfigurierbar. Das ersetzt nicht ein dediziertes FinOps-Tool wie LangFuse für Engineering-Teams – aber es liefert dem CFO genau die Sicht, die er braucht.
EU-Hosting und DSGVO im Standard. Dedizierter Server in Deutschland, DSGVO-konformes Setup inkl. Auftragsverarbeitungsvertrag, ISO-27001-Roadmap, vorbereitet auf die EU-AI-Act-Anforderungen. Das ist nicht direkt FinOps-relevant – aber es vermeidet eine ganze Klasse an Doppel-Audits und Beratungstagen, die parallele Tool-Bauchläden mit sich bringen.
Workshops für den schnellen Einstieg. Wer 2026 sauber starten will, kommt nicht um die Frage herum: Welche Use Cases sind den Aufwand wert, welche nicht? Genau dafür haben wir unsere KI-Workshops entwickelt – mit Use-Case-Backlog, ROI-Bewertung und Quick-Win-Empfehlung. Kein Beratungs-Tourismus, sondern ein Impact-Report, mit dem das Buying-Center direkt arbeiten kann.
Plotdesk ist kein FinOps-Tool im engeren Sinne – wir ersetzen weder LangFuse noch Azure Cost Management. Aber wir machen es strukturell schwer, in die Token-Falle zu laufen: Multi-Modell ist Default, Caching ist eingebaut, Telemetrie ist Standard. Wer Plotdesk produktiv betreibt, hat die Stufe 2 des Reifegradmodells am Tag 1 erreicht – statt sie nachträglich zu retrofitten.
12. Fazit – was Sie aus diesem Artikel mitnehmen sollten
FinOps für KI ist 2026 keine Spezial-Disziplin für Tech-Konzerne. Die State-of-FinOps-Daten sind eindeutig: Die Welle ist da, sie ist groß, und sie macht vor mittelständischen Budgets nicht halt. Wer früh handelt, fährt mit – wer wartet, zahlt drauf.
Drei Erkenntnisse zum Mitnehmen:
1. Inferenz ist der eigentliche Kostenblock. 80–90 % der laufenden KI-Ausgaben entstehen pro Anfrage, nicht beim Training. Jedes Architektur-Detail (Modell-Mix, Caching, Output-Limits, RAG-Tuning) wirkt direkt auf den Steady-State – nicht erst nach Jahren.
2. Die größten Hebel sind technisch trivial. Prompt Caching aktivieren, Batch API nutzen, Small Models für einfache Tasks routen – das sind keine PhD-Themen, sondern Sprint-Aufgaben. Wer sie systematisch umsetzt, halbiert die KI-Rechnung typisch im ersten Quartal.
3. Disziplin schlägt Tool. Es gibt keine FinOps-Suite, die das Problem ohne organisatorisches Setup löst. Ein klarer Owner zwischen Engineering und Finance, ein gemeinsames Use-Case-Register mit dem KI-Beauftragten, KPIs in CFO-Sprache – das ist der Unterschied zwischen „wir messen" und „wir steuern".
Wer 2026 KI ernsthaft produktiv einsetzt und das ohne Budget-Überraschung tun will, kommt um diese Disziplin nicht herum. Die guten Nachrichten: Die Hebel sind dokumentiert, die Preise sind transparent, und der Werkzeugkasten ist offen verfügbar. Das Verbleibende ist eine Frage der Priorisierung – und der Frage, ob die Kostensteuerung vor dem ersten Quartals-Schock startet oder erst danach.
Drei sofort umsetzbare Schritte
Diese Woche: Bestandsaufnahme aller laufenden KI-Workloads – wer hat welche Account-Keys, wo entstehen die Kosten? Wenn Sie keine zentrale Antwort haben, ist das Problem 1.
Diesen Monat: Token-Telemetrie pro Use Case aktivieren – egal ob über LangFuse, Plattform-native Reports oder einen einfachen Proxy-Layer. Ohne diese Sichtbarkeit ist alles weitere Bauchgefühl.
Dieses Quartal: Hebel 1–3 (Prompt Caching, Batch API, Multi-Modell-Routing) auf die Top-3-Use-Cases anwenden. Realistisches Ziel: 30–50 % Kostenreduktion, ohne dass eine produktive Funktion eingeschränkt wird.
Weiterführende Artikel im Plotdesk-Magazin
Wer dieses Thema vertiefen möchte, findet im Plotdesk-Magazin angrenzende Analysen mit unterschiedlicher Detailtiefe:
- Total Cost of Ownership: Was eine KI-Plattform wirklich kostet – die statische Investitionsperspektive, ergänzend zur dynamischen FinOps-Sicht in diesem Artikel.
- Multi-Modell-Strategie: Vendor-Lock-in vermeiden – tieferer Blick auf den wichtigsten Architektur-Hebel.
- Token-Kosten im Vergleich – reine Preisliste der Modelle, ergänzend zur strategischen Sicht hier.
- KI-Agenten im Unternehmen 2026 – der Use-Case-Typ, der die größten Kostenfallen produziert.
- Build vs. Buy: Die wahren Kosten einer KI-Plattform – die Entscheidung, die der FinOps-Setup vorausgeht.
- KI-Richtlinie für Unternehmen 2026 – die Governance-Klammer, in die FinOps integriert werden sollte.
Wenn Sie mit Ihrem Team konkret an einem FinOps-Setup für KI arbeiten wollen, schauen Sie sich auch unsere KI-Workshops an. Wir liefern einen vorstandstauglichen Impact-Report mit priorisierten Use Cases, ROI-Schätzung pro Case und einer 3/6/12-Monats-Roadmap.


